Abstract
Some Learning from Demonstrations (LfD) methods handle small mismatches in the action spaces of the teacher and student. Here we address the case where the teacher's morphology is substantially different from that of the student. Our framework, Morphological Adaptation in Imitation Learning (MAIL), bridges this gap allowing us to train an agent from demonstrations by other agents with significantly different morphologies. MAIL learns from suboptimal demonstrations, so long as they provide some guidance towards a desired solution. We demonstrate MAIL on manipulation tasks with rigid and deformable objects including 3D cloth manipulation interacting with rigid obstacles. We train a visual control policy for a robot with one end-effector using demonstrations from a simulated agent with two end-effectors. MAIL shows up to 24% improvement in a normalized performance metric over LfD and non-LfD baselines. It is deployed to a real Franka Panda robot, handles multiple variations in properties for objects (size, rotation, translation), and cloth-specific properties (color, thickness, size, material).
Video
Overview
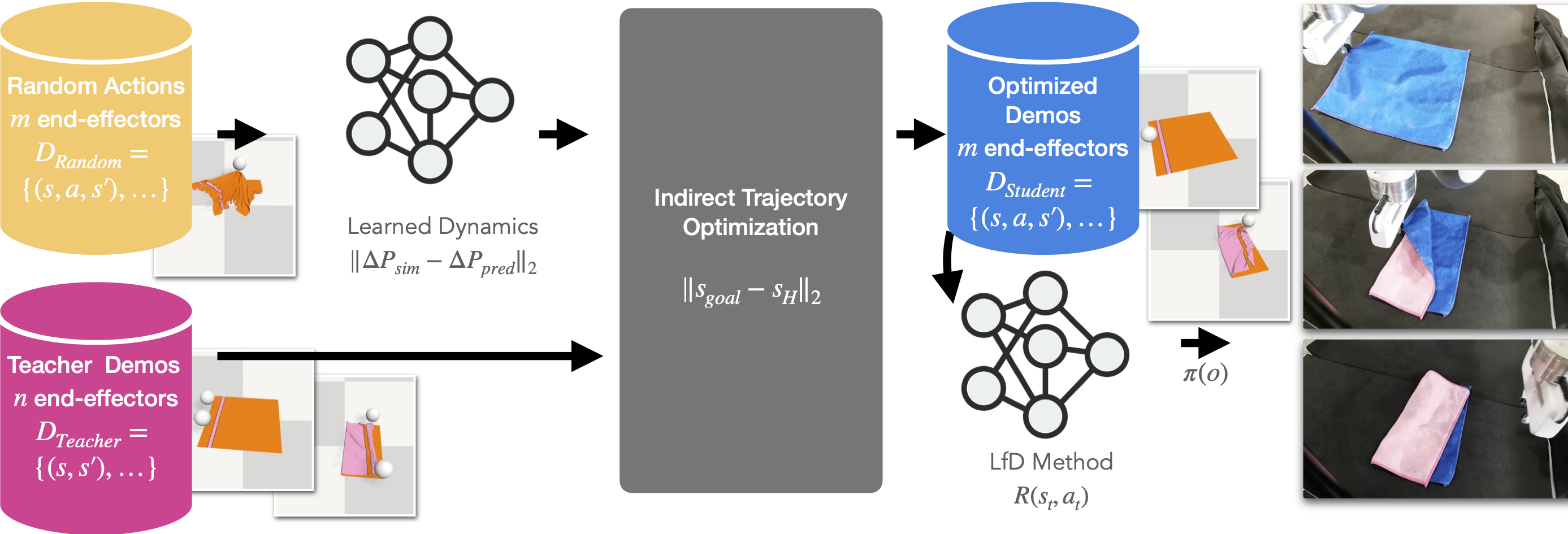
Learning from Demonstration (LfD) is a set of supervised learning methods where a teacher (often, but not always, a human) demonstrates a task, and a student (usually a robot) uses this information to learn to perform the same task. Some LfD methods cope with small morphological mismatches between the teacher and student (e.g., five-fingered hand to two-fingered gripper). However, they typically fail for a large mismatch (e.g., bimanual human demonstration to a robot arm with one gripper). The key difference is that to reproduce the transition from a demonstration state to the next, no single student action suffices - a sequence of actions may be needed.
We propose a framework, Morphological Adaptation in Imitation Learning (MAIL), to bridge this mismatch. We focus on cases where the number of end-effectors is different from teacher to student, specifically 3-to-2, 3-to-1, and 2-to-1. It does not require demonstrator actions, only the states of the objects in the environment making it potentially useful for a variety of end-effectors (pickers, suction gripper, two-fingered grippers, or even hands). It uses trajectory optimization to convert state-based demonstrations into (suboptimal) trajectories in the student's morphology. The optimization uses a learned (forward) dynamics model to trade accuracy for speed, especially useful for tasks with high-dimensional state and observation spaces. The trajectories are then used by an LfD method, which is adapted to work with sub-optimal demonstrations and improve upon them by interacting with the environment.
Results
White sphere in simulation indicates end-effector.
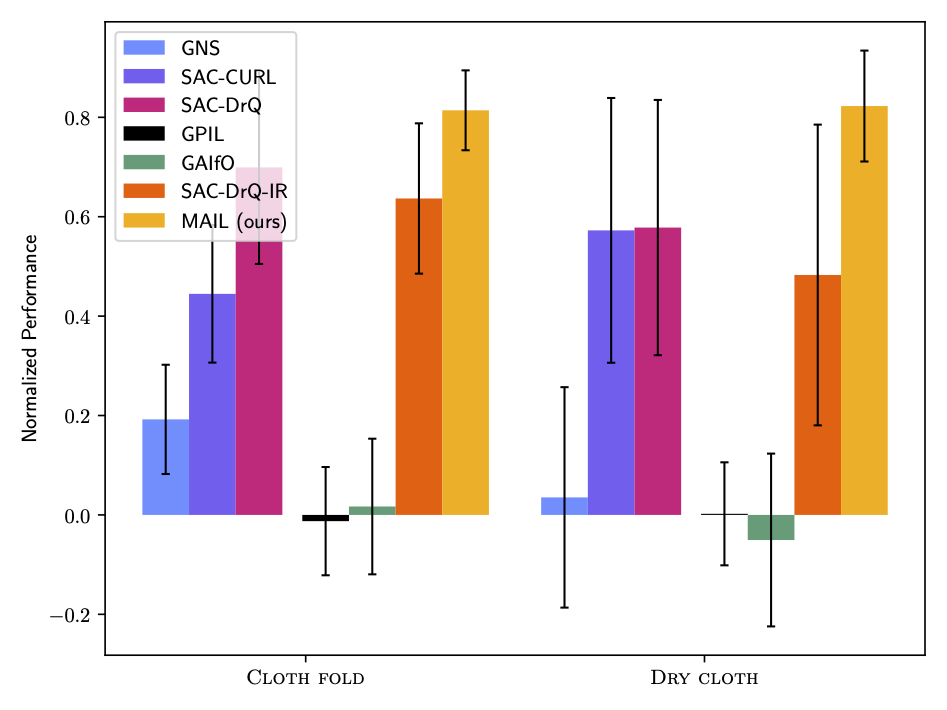
Cloth Fold Comparison
The objective is to fold a flattened cloth into half, along an edge, using two end-effectors. The performance metric is the distance of the cloth particles left of the folding line, to those on the right of the folding line.
Dry Cloth Comparison
The objective is to pick up a square cloth from the ground and hang it on a plank to dry. The performance metric is the number of cloth particles (in simulation) on either side of the plank and above the ground.
Cloth Fold Sim2Real
- Zero-shot sim2real.
- Adjusts to cloth size, color, material, thickness, pose.
Dry Cloth Sim2Real
- Zero-shot sim2real.
- Adjusts to cloth size, color, material, thickness, pose.
- 3D cloth manipulation with a rigid obstacle.
Generalizing n-to-m end-effector transfers
Simulation
Examples of generalizing to different n-to-m end-effector transfers:
- 3-to-2 transfer.
- 3-to-1 transfer.
- 2-to-1 transfer, if we use rollouts from m=2 above as teacher demonstrations for student with m=1 end-effector.
Real World
- Zero-shot sim2real.
SOTA Performance Comparisons
For each training run, we used the best model in each seed's training run, and evaluated using 100 rollouts across 5 seeds, different from the training seed. Bar height denotes the mean, error bars indicate the standard deviation. MAIL outperforms all baselines, in some cases by as much as 24%.